[dbt] How to validate the compiled version of dbt models for SQL correctness
dbt is the T in ELT (Extract Load Transform). It doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse.
If you’ve been working with dbt for a while, you probably noticed that dbt doesn’t give you any option to validate the changes you’ve made on dbt models for sql correctness. That’s a problem!
The lack of validation functionality is mostly because the diverse range of databases, which dbt wants to support. If some of the popular database doesn’t have the functionality to validating the sql for correctness without executing it, it becomes a problem for the dbt adapter. And it’s one of the reason why dbt doesn’t provide the validation functionaly out-of-the box.
The type of changes for the model might be different, but we’ll concentrated on two of them:
- changes in dbt model business logic (mostly changes in sql)
- changes in dbt-model configuration (dbt-related changes, like partitioning, dbt-hooks, tests, etc)
We want to prevent the situations, where any change in your dbt models might break the production pipelines. In a usual setup, your dbt models are running in the modingn once a day, and if you as a Data Team failed in the validation process, probably your morning dbt pipeline will fail. So, we want to somehow prevent it from happening. Ideally, we want to catch these cases during development pipeline, maybe it should be integrated with your development pipeline, so you’ll get the error message instantly, during the dev process, not in the morning when the pipeline is already failed. So, this validation is cases of invalid state must fail as-fast-as-possible, even more it should fail in merge request phase, before being delivered to production envirounment.
Is there any known solution we can grab for us?
Unfornutelly, as for end of 2023, there is no available option for the dbt-world addressing for the above issue. I heard a lot of inhouse-solutions, heavely coupled with their infrastacture and setup. If you found any suitable option, please let me know.
We’re going to discuss the possible options to solve the challenge!
How the validatiopn pipeline should looks like?
First things first! Let’s imagine how the development pipeline might looks like if we had a validation feature inside dbt-core functionality. Probably, we can start with the developer env setup. Usually, developers are working with their dev-env which is safe zone for them. This setup must be isolated from the production, so any changes/modification in dev env doesn’t have effect on the prod env. So, let’s keep this idea in mind.
The second idea, is that the changes in dev must be applicable to the prod env, and vise versa. So, devs must have abitility in git like approach pull the latest version of tables from prod env. So, devs can easily develop their models with the latest version of models.
The third idea is that the devs can easy from CLI/GUI run the validation pipeline agianst the changes he/she made.
What’s the main requirements for the validation pipeline?
In terms of requirements, the validation pipeline should have the following features:
- undependant from any database specifics
- able to validate pure ANSI SQL
- able to validate dbt models compiled to ANSI SQL
- able to validate dbt-test against compiled compiled to ANSI SQL. Here by tests we’re assuming only correctness of the tests, not data tests!
- able to validate dbt pre and post hooks
- able to validate dbt sources, snapshots, and seeds
- provide an easy way to extend the validation logic (add-ons)
- provide an interface for the interaction
- an easy way to setup in the env
So, how we can create our in-house validation process?
First of all, we should make sure that our target database supports EXPLAIN command or has some alternative feacture which covers the same functionality. In this article, I’ll demostrate the approach on Databricks.
Second, we should have a version control system, like GitLab, GitHub, etc. The main requirement for these SVNs is to be able provide CI/CD features. And the overall pipeline should look similar to this figure
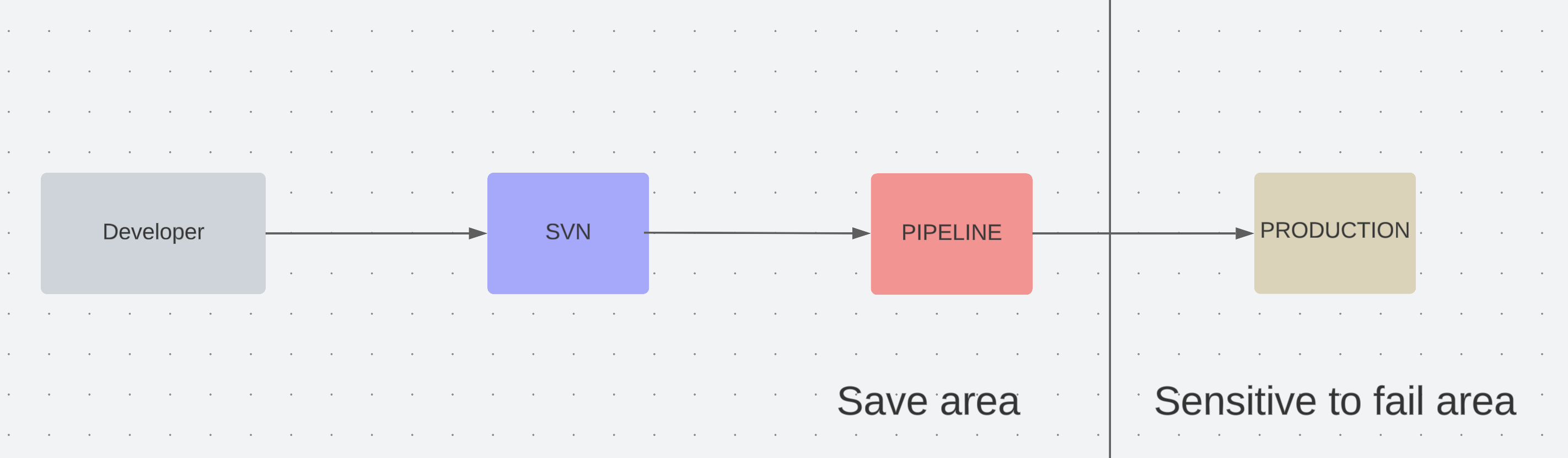
So, let’s say we have databricks as an SQL Engine, and dbt-models are stored in the GitLab project. We want to validate the all dbt model changes in Merge Request which were opened by ourselves or teammates. If the validation fails, obviously, the MR’s pipeline must fail and block the delivery process until the fail will be fixed.
Gitlab CI pipeline structure
The definition of the GitLab pipeline might look the following, where we’re extracting the list of changed dbt models in the Merge Requests and calling compile.sh script with the list of changed files. The compile script, as the name hints should generate a compiled version of each given dbt model and all children of these models, excluding the grandchildren models.
# .gitlab-ci.yml
dry_run:
image: $GITLAB_CONTAINER_MR_IMAGE
stage: test
needs: ["merge_request_docker_image"]
environment:
name: production
script:
- files=`git diff --name-only --diff-filter=d $CI_MERGE_REQUEST_TARGET_BRANCH_NAME..$CI_MERGE_REQUEST_SOURCE_BRANCH_NAME -- 'models'`
- echo "Changed files\n ${files[*]}"
- if ! $files; dbt deps; fi
- if ! $files; then dbt debug; fi
- if ! $files; then ./scripts/compile.sh "${files[*]}"; fi
- if ! $files; then ./scripts/dry_run.sh target/compiled/analytics_dbt/models; fi
only:
- merge_requests
compile.sh script
A straightforward bash script, which compiles the given dbt models and the children of the model.
# compile.sh
#bin/bash
set -e
echo "Running compile script with parameters";
# shellcheck disable=SC2068
echo $@;
for sql_file in $1; do
model=$(echo "$sql_file" | rev | cut -d/ -f1 | rev)
echo "Compiling $model..."
dbt compile -s "$model"+1 --target production
done
dry_run.sh script
The script checks if a folder path has been provided as an argument when the script is run. If no folder path is provided, the script will display an error message and exit with an exit code of 1. Then script uses the find command to find all SQL files recursively inside the provided folder and store the total number of files in the “total” variable. Then the list of files sorts alphabetically. The while read -r -d $'\0' loop is used to iterate through each file.
For each file, the script displays a progress indicator showing the number of files remaining and the total number of files. Then it uses the dbt run-operation command to call is_valid_sql macros which validates the sql content of the file. The “—args” flag is used to pass a parameter to the dbt command, and the “—target” flag is used to specify the target database to run the command against. Finally, the script uses the “rm” command to delete the current file being processed, this allows the script to change the progress indicator.
# dry_run.sh
set -e
if [ -z "$1" ]; then
echo "Please call '$0 <folder>' to run this command!"
exit 1
fi
path=$1
echo "Running dry_run script in $path folder"
total=$(find "$path" -name '*.sql' | wc -l )
total_no_whitespace="$(echo "${total}" | tr -d '[:space:]')"
# Find all sql files recursively inside the given folder
find "$path" -name '*.sql' -print0 | sort | while read -r -d $'\0' file
do
# progress indicator
left=$(find "$path" -name '*.sql' | wc -l)
left_no_whitespace="$(echo "${left}" | tr -d '[:space:]')"
remaining=$((total_no_whitespace-left_no_whitespace + 1))
echo "[$remaining/$total_no_whitespace] Validating $file..."
# validate sql content of the file
dbt run-operation is_valid_sql --args "{sql_query: \"$query\"}" --target production
# Deleting the sql file to be able change the progress indicator
rm $file
done
is_valid_sql dbt macros
This is a dbt macro that is used to check if a given SQL query is valid. The macro begins by defining the input parameter “sql_query”, which is the SQL query that needs to be checked for validity. The next line uses the “run_query” function to execute the “explain” command on the provided “sql_query” parameter. The result of the explain command should be either a Physical Plan of the execution of the given sql query or the Error message indicating the root cause of the error. If the first row of explain command result started with ”== Physical Plan ==” it means sql query is valid, otherwise it’s not. If the query is not valid the macro raises an error, indicating that the provided query is not compilable.
{% macro is_valid_sql(sql_query) %}
{{ log("Running is_valid_sql macros with params: ") }}
{{ log("sql_query: " ~ sql_query ) }}
{% set explain_result = run_query('explain ' + sql_query) %}
{% set is_valid = "== Physical Plan ==" in explain_result.rows[0].values()[0] | as_bool %}
{{ log("is_valid: " ~ is_valid ) }}
{% if not is_valid %}
-- We want exit from the macros with non 0 code to indicate that the query is not compilable
{{ exceptions.raise_compiler_error("Provided query is not compilable") }}
{% endif %}
{% endmacro %}